
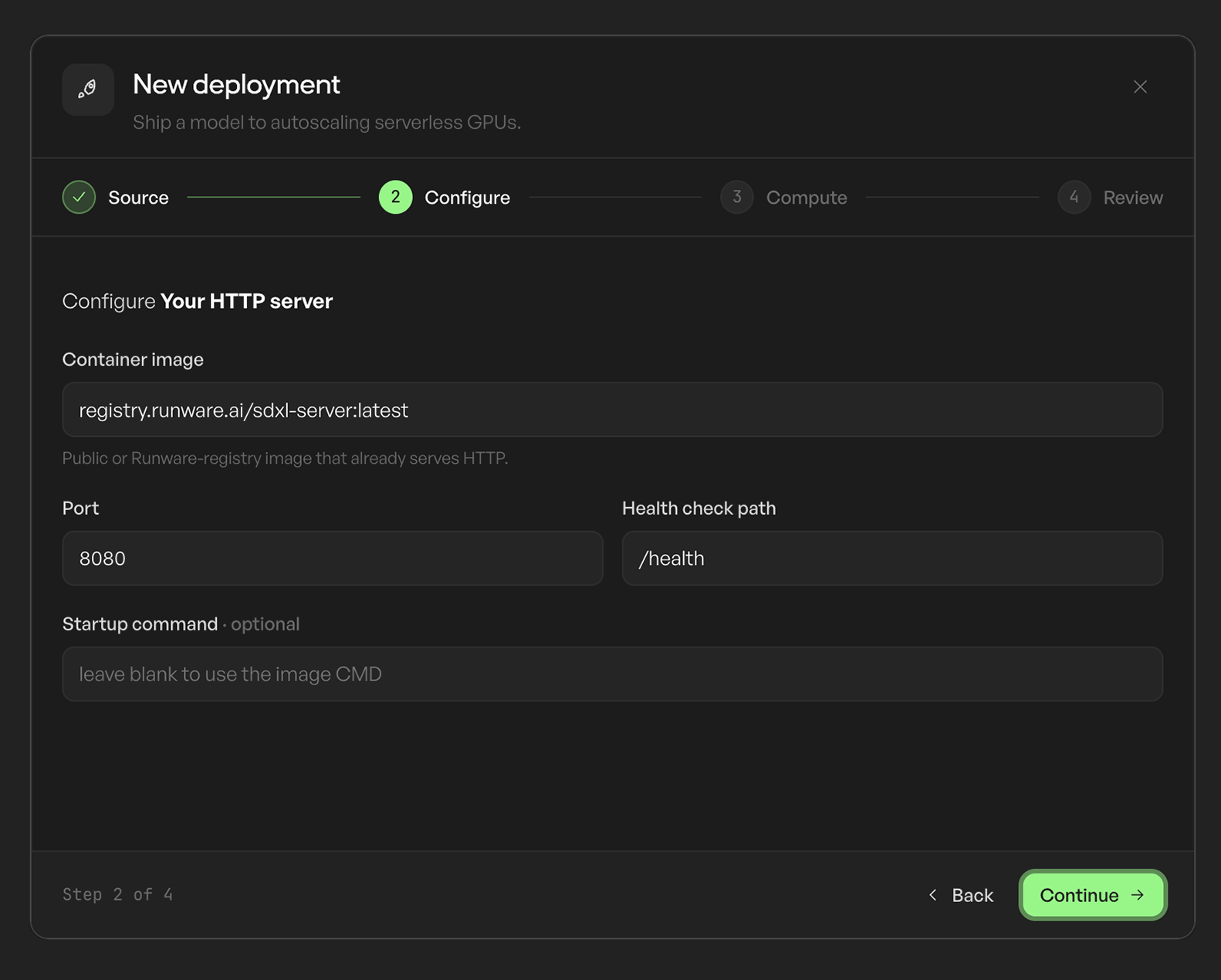
Scale from zero to thousands
Burst on demand around your real traffic, then settle back to nothing. Reserve capacity when you need guaranteed throughput, region, or priority.
Deploy and scale your AI workloads on Runware's optimized hardware. Pay only for the runtime you use, billed by the second, with no infrastructure to manage and capacity that scales with demand.
Pay only for the time you use - not cold starts, not idle capacity. Flexible by default with no commitment, or reserve capacity for a lower rate. Runware's optimized hardware and software acceleration bring serverless price points down to levels usually reserved for long-term bare-metal rentals.
You pay for runtime, not infrastructure ownership. The meter runs while your application does. A cost-efficient GPU covers most inference; higher-memory and frontier classes are available from our wider pool, so you can match the hardware to your workload.
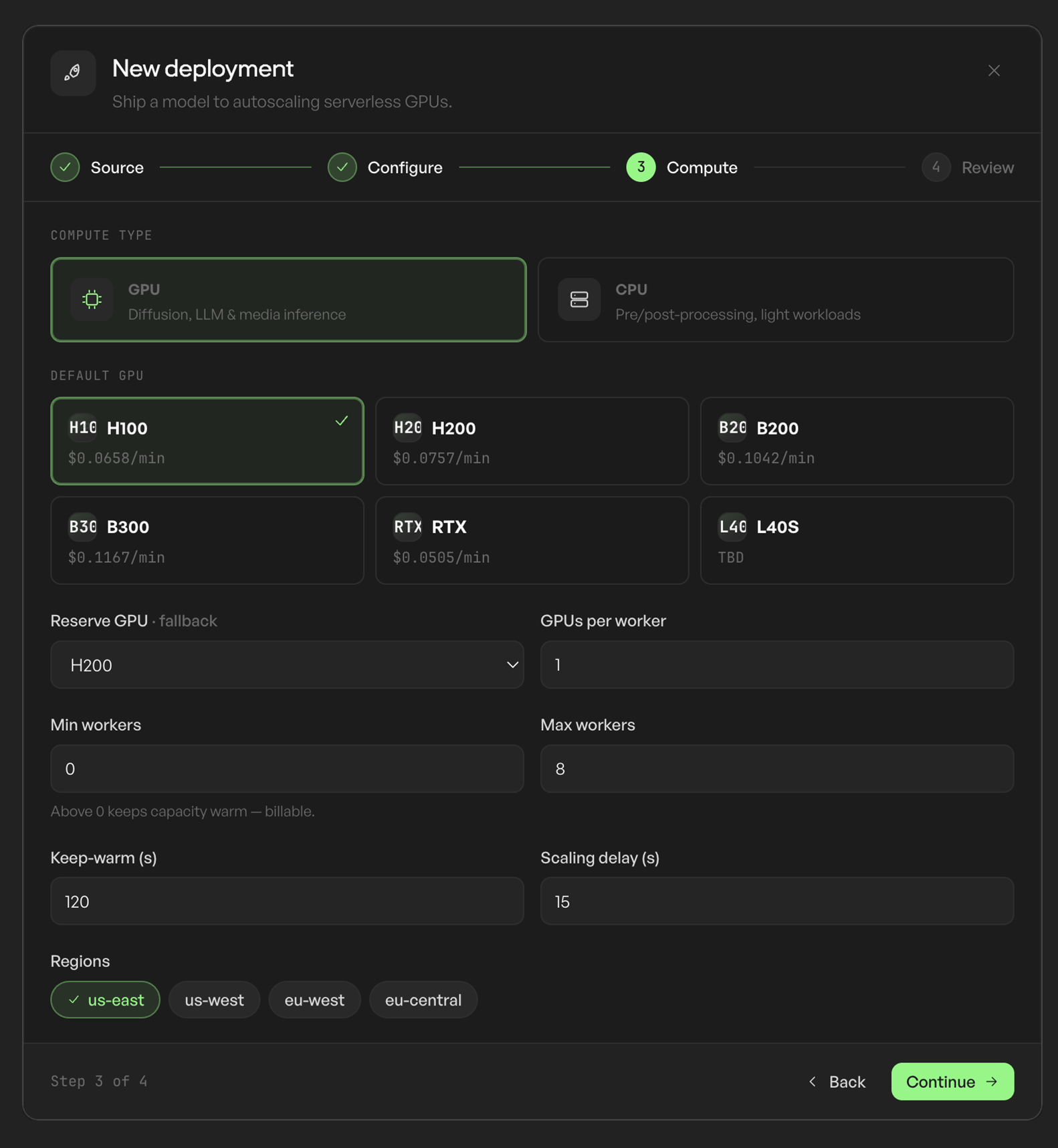
Run flexible with no commitment and per-second billing, or reserve capacity for guaranteed availability, concurrency, and region at a lower rate. Reservation terms are optional and scoped to your scale.
Lock in lower economics and deployment priority with a reservation when your workload is steady. No commitment required when it isn't.
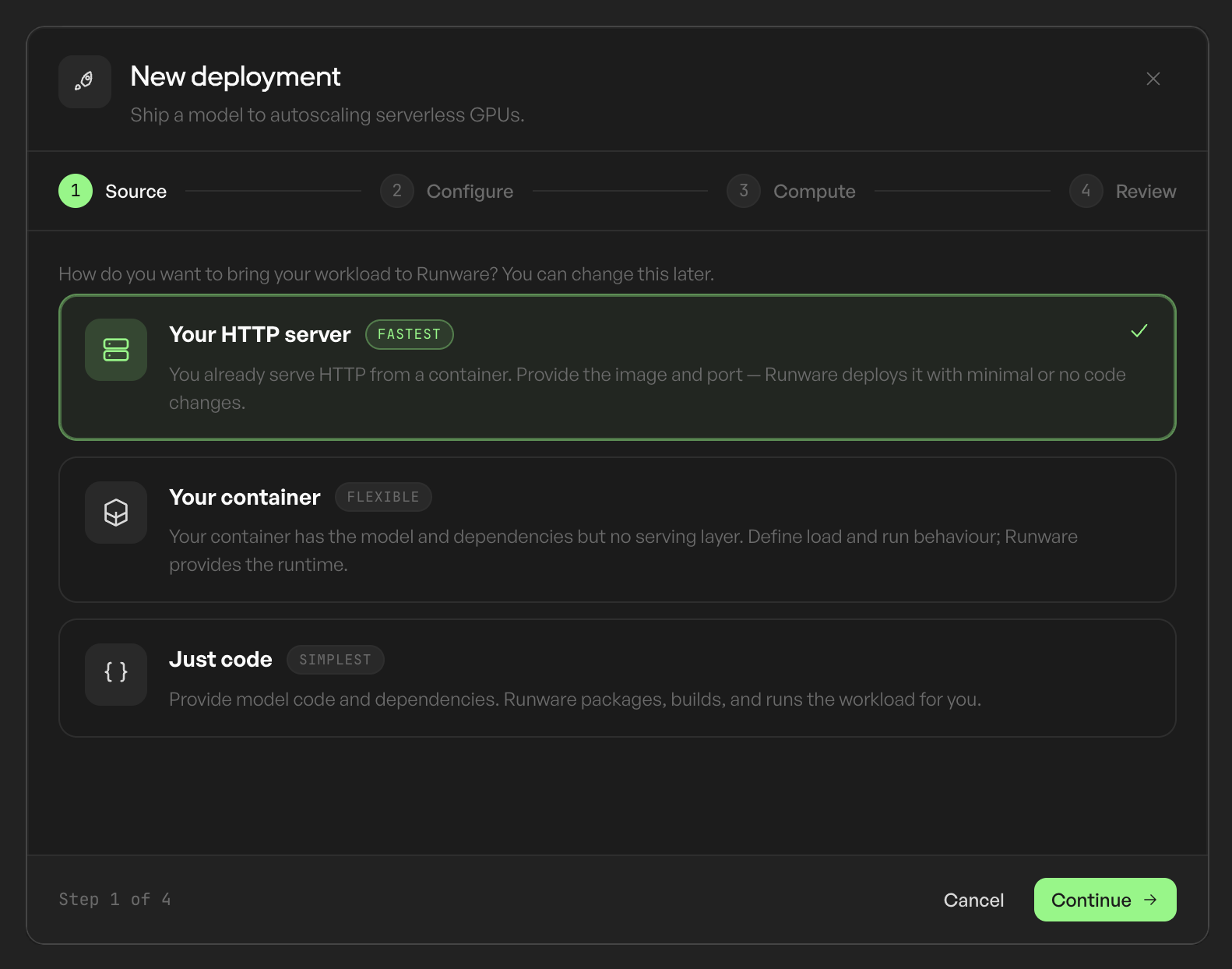
Bring a container, an existing server, or model code and get a production endpoint that scales with traffic, with support for both fast synchronous calls and long-running jobs. Scaling, routing, and recovery are ours to run, not yours.
Source, configure, compute - step through the deploy flow and you have a live, autoscaling endpoint.
Code, a container, an existing server, or your application. Private registries and runtime secrets included.
A cost-efficient default covers most inference. Reach for higher-memory or frontier classes from the wider pool when a workload needs them.
Burst on demand for peaks, then settle back to normal. Reserve a capacity envelope when throughput must be guaranteed.
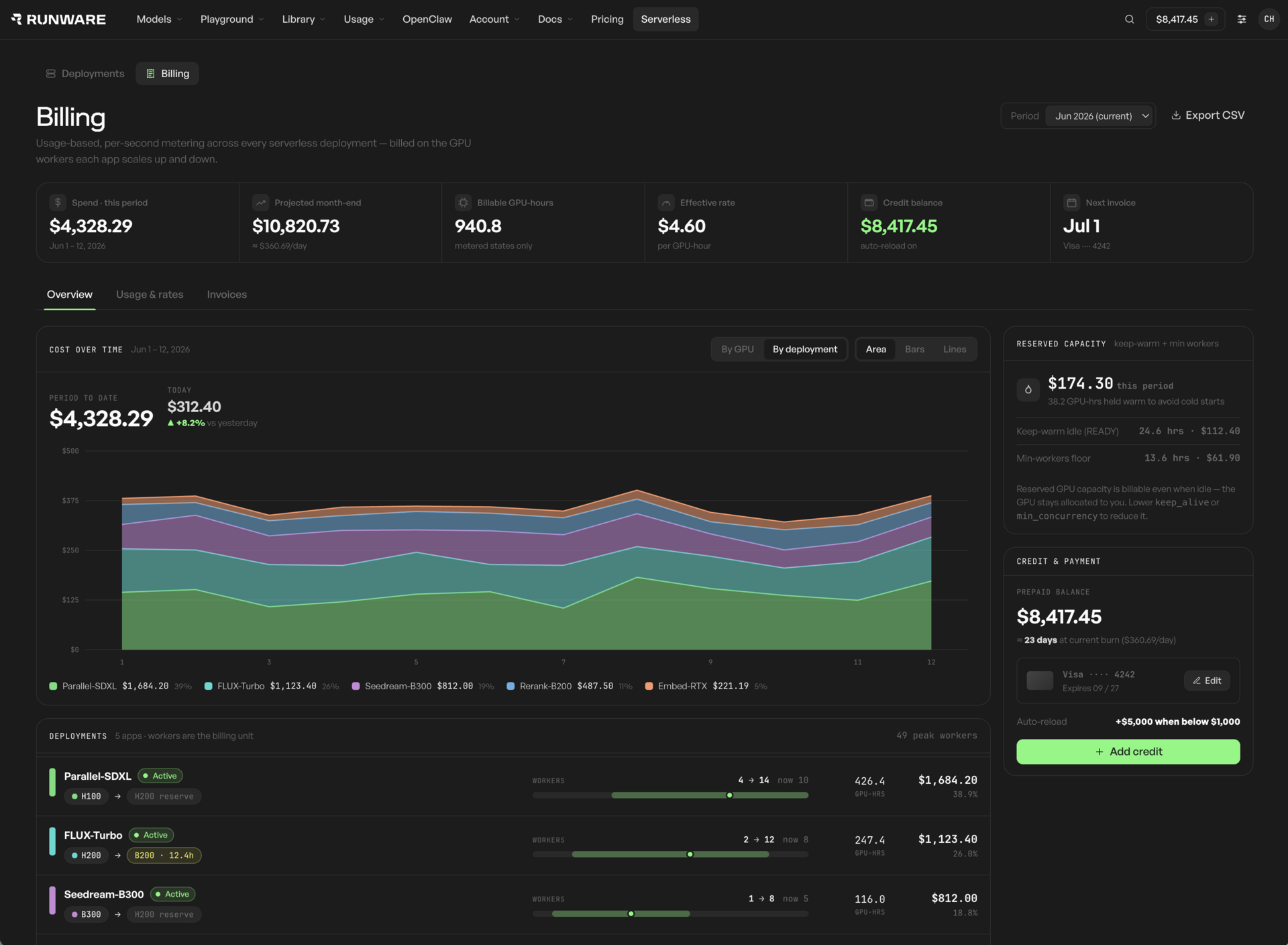
Logs, worker state, latency, errors, and live cost. You always know what's running and exactly what you're saving against the alternatives.
Everything below ships with every application. No enterprise-tier gating on the basics.
Burst on demand around your real traffic, then settle back to nothing. Reserve capacity when you need guaranteed throughput, region, or priority.
You pay while your application runs, not for idle capacity you own. The clearest way to keep inference costs tied to demand.
Scaling, routing, and recovery are handled for you. You deploy; we keep it healthy and serving traffic.
Fast calls return immediately; long renders and big batches are queued and executed for you, without timeout gymnastics.
Application state, latency, errors, and live cost visibility built in. The dashboard you'd build yourself, already there.
Pull private images and inject runtime secrets safely. Your code and weights stay yours.
You're billed by the second while your application runs or is held warm. Reserved capacity is billable even when idle, because you're holding it.
On-demand waits, image pulls, and platform failures are our cost, not yours.
No, and that's kind of the point. You never touch a node. You deploy an application; we run, scale, route, and meter it. You pay for runtime, not for babysitting infrastructure.
Code, containers, existing servers, and custom inference applications, plus CPU-heavy app workloads and GPU workloads across image, video, audio, 3D, LLM, and custom apps. If it serves traffic, it fits.
Yes, and at scale you'll want to. On-demand covers bursts; reserved envelopes give you guaranteed availability, concurrency, region, and deployment priority, up to 50% lower pricing depending on duration, availability, and scale.
Per second of runtime against the GPU class you choose, shown as per-hour equivalents. You're billed while your application is running or held warm. On-demand scheduling waits, image pulls, and platform failures are our cost. Reserved capacity is billable even while idle, because you're holding warm capacity.
A cost-efficient default covers most inference. Higher-memory and frontier GPU classes are available from our wider pool, so you can match the hardware to your workload. Reserved clusters are scoped per deployment; talk to us if you need them.
Deploy an application, pick a profile, pay for runtime. If our math doesn't beat your current bill, don't switch, but do check the math.
To request access to the Beta, tell us more about your needs.