
List it in the model directory
Publish your model to the Runware model directory and API so any developer can discover and call it. You set the unit price; we handle distribution, scaling, and billing.
Our team works with yours to turn your model into a dedicated, production-ready API, public through the model directory or private on a dedicated endpoint. We handle deployment, scaling, and operations, and you pay per inference for what you use.
Bringing a model into production is real work, so we do it with you. Our team scopes the model, helps you define its API, picks hardware, and tunes the serving path - then you serve it through a dedicated API and pay per inference for what you use.
Weights, artifacts, dependencies, and target scale. Onboarding is architecture-dependent, so we confirm your model family is supported up front. Proprietary and fine-tuned models stay yours.
You define the API for your model - its inputs, outputs, request/response shape, and validation - and we help shape the schema with best practices, so it's clean and consistent to call.
Together with your engineers we benchmark on the hardware that would serve it and tune the serving path, batching, and placement. You approve the economics before going live.
Your model goes live as a scalable production API - public in the model directory or private on a dedicated endpoint. Capacity, routing, and the pager are ours.
Not every model belongs in a public catalog. Deploy yours where it fits: listed publicly for any developer to call, or private on a dedicated endpoint only your team and partners can reach. Same platform, same economics underneath.
Publish your model to the Runware model directory and API so any developer can discover and call it. You set the unit price; we handle distribution, scaling, and billing.
Keep the model yours. A dedicated API endpoint only your team and approved partners can reach, with reserved throughput and isolation. No public listing.
You pay for what you consume - per token, image, generated second, or asset, depending on your model. When you deploy, we automatically profile your model on the hardware that serves it and calculate your price per inference from that. Want guaranteed capacity and predictable cost? Optionally commit to throughput up front for a lower effective rate.
scoped with your team workload 10s video generation target price ≤ 40% of list price worked through together… ✓ model profiled on candidate hardware ✓ serving path and batching tuned → result: target met, economics approved
Pay for the tokens you generate. Commit to a throughput level when you want guaranteed capacity and a predictable bill.
Consumption · optional committed throughputPay for the seconds you generate. Reserve concurrency when a media-heavy product needs guaranteed capacity.
Consumption · optional reserved concurrencyPay per request or output. Reserve volume when you want fixed economics without capacity planning.
Consumption · optional reserved volumePay for output, not idle infrastructure.Consumption pricing means you're not paying for GPUs you aren't using - and when you need guaranteed capacity, an optional commitment gives you predictable cost, typically below running the same workload yourself. Your price per inference is calculated automatically from your model's profile on deployment.
A production setup without the effort of capacity management, cluster operation, monitoring, frontend builds, and API development. We run it end-to-end; you just pay for inference.
You define the API around your model - its inputs, outputs, and validation - with our best-practice guidance, so it's consistent and easy to integrate, with auth and errors handled for you.
A hosted playground for your deployment so product, sales, and partners can try the model without writing code.
Consumption pricing by default; reserve throughput or concurrency when your product needs guaranteed capacity.
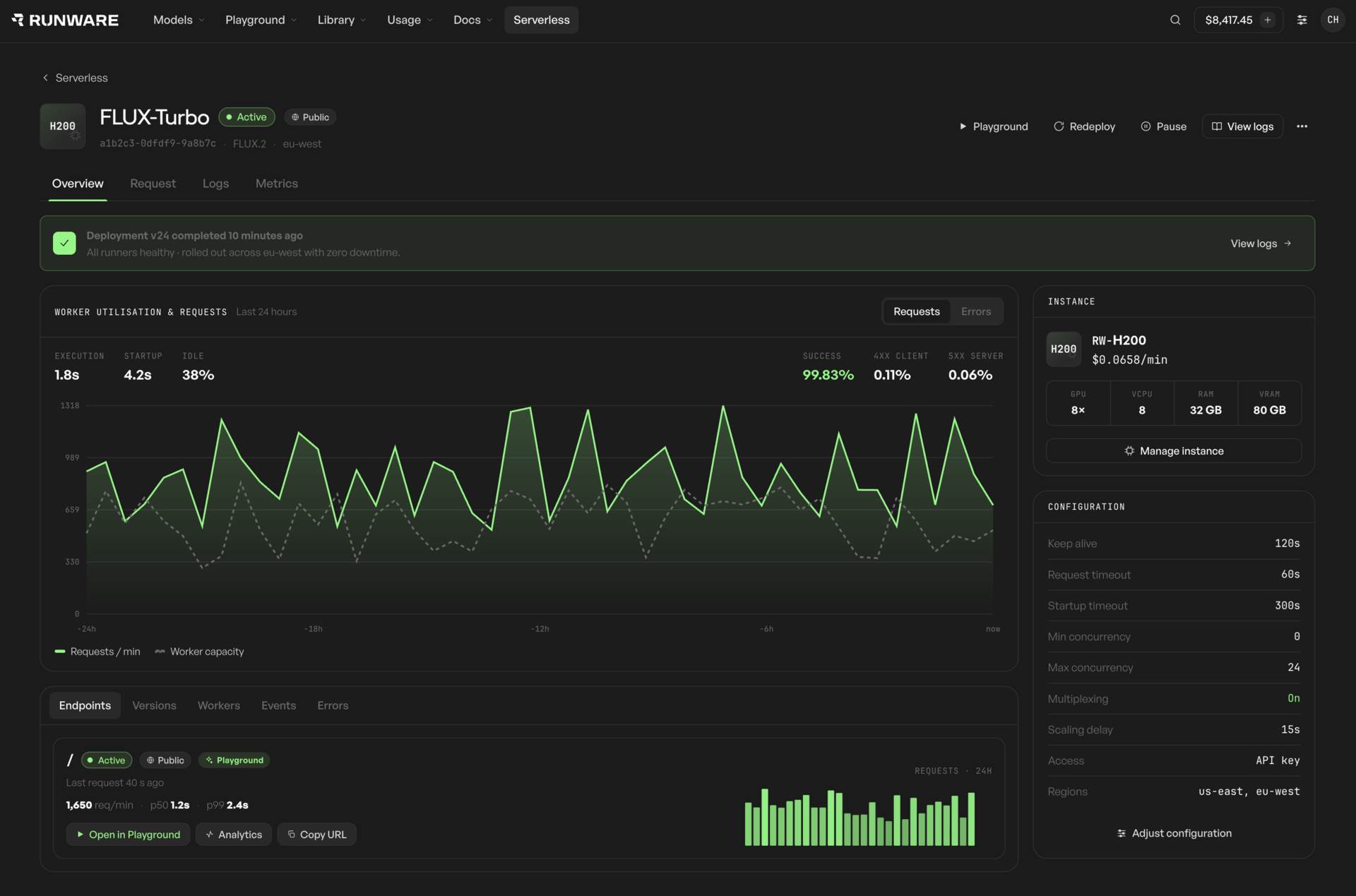
Request logs, usage breakdowns, latency, errors, and cost visibility across your dedicated deployment.
Your deployment spreads across many locations. Redundancy built in, no single mega-cluster to fail.
Serving path, concurrency, batching, placement, and unit economics, worked through with your team against real traffic.
Model API is our catalog: models we or our partners already host, ready to call. API Gateway is the other direction. You bring your model, we deploy and optimize it, and you get a production API, public in the model directory or private on a dedicated endpoint only you share.
Yes. Deploy to a dedicated private endpoint only your team and approved partners can reach, with reserved throughput and isolation and no public listing. Or list it publicly in the model directory if you want any developer to call it.
Model providers commercializing their own models, AI products with proprietary or fine-tuned models, and enterprise teams that want a production API without building an inference platform first.
A managed, guided process. Our team works with yours to define the API, choose hardware, and tune the serving path. It's not a one-click upload, and that's deliberate, because getting a model production-ready is real work.
Onboarding is architecture-dependent, and our upload workflows support a specific set of model families today. The fastest way to find out is to tell us what you're running. If it's supported, we'll scope the work with you.
Helping you define the API for your model, choosing and configuring hardware, tuning the serving path, scaling, routing, and operations, worked through with your engineers against your real traffic.
You pay per inference for what you consume. If you want guaranteed capacity and predictable cost, you can optionally commit to throughput up front for a lower effective rate.
Deployment, optimization, scaling, the API surface, the pager - ours. Your team gets back to building the product.
To request access to the Beta, tell us more about your needs.