


Purpose-built inference servers
Servers, racks, cooling, and networking we design and operate for one job: efficient AI inference at the lowest overhead.
Deploy containerised AI workloads without managing the underlying infrastructure. Scale with demand, access best-in-class GPUs through a production-ready API, and pay only for the runtime you use, billed by the second.
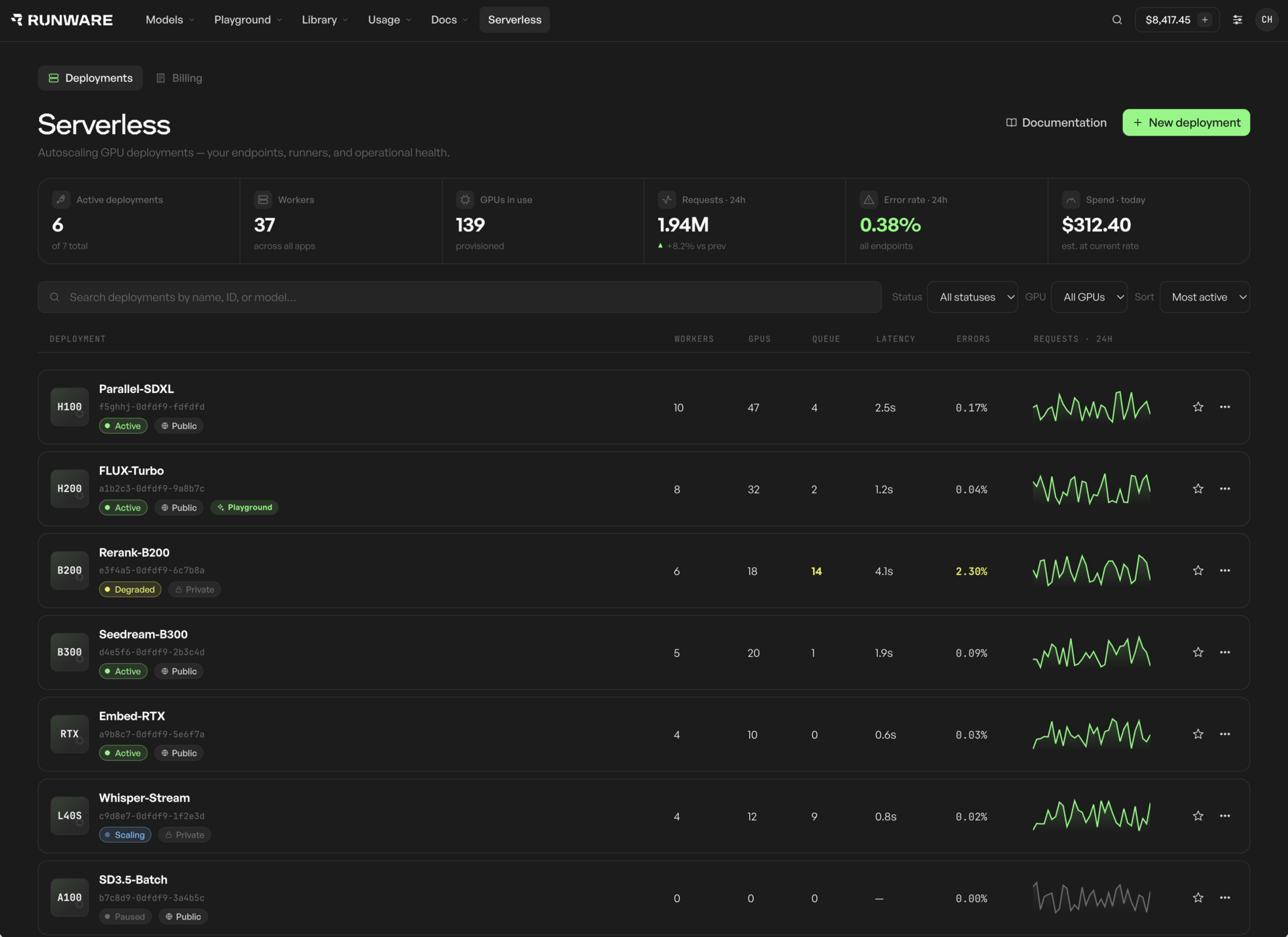
Serverless Compute runs your own workloads with per-second billing, on infrastructure managed by Runware. API Gateway deploys your model behind a dedicated API, public or private, with scaling and operations managed for you.
Your code on our GPUs. Billed by the second.
Deploy containers, services, or scripts without managing infrastructure. You keep runtime control; Runware scales, meters, and operates the fleet.
Your model behind a dedicated API. Public or private.
Ship with scaling, ops, and observability handled for you. List in the model directory or restrict access to your team and partners.
Engineered on infra we built and own, tuned for inference specifically. You pay for what you use: per second on Compute, per inference on Gateway. Never for idle capacity.
That's what brings serverless pricing down to bare-metal levels, however you choose to scale.
Custom servers, racks, cooling, storage, and networking, designed for one job: AI inference throughput.
We keep utilization high and model starts fast, so each node does more useful inference work and spends less time idle.
We pass our lower cost per inference (token, image, video, or any asset) to you in the price, because our stack is engineered for efficiency.
$1.99/GPU-hour at launch, while much of the market sits at $3–4+. Because we run our own optimized hardware, we can pass the savings straight to you, and launch pricing is limited, so lock in your rate early.
View launch pricingWe benchmark your model as-is on the exact hardware path that would serve it, then work with your engineering team to optimise it further, so you can validate the economics before you commit. We'd rather show you results on your model than publish numbers from ours.
We're scaling a distributed network of inference capacity across many locations. Burst when you spike, settle back when you don't, and reserve guaranteed throughput when you need it.
We design and operate purpose-built inference infrastructure for efficiency, then match your workload to the right GPU from a broad pool. You get the performance without owning, naming, or managing any of it.
Servers, racks, cooling, and networking we design and operate for one job: efficient AI inference at the lowest overhead.
Hardware configurations matched to specific workloads, including designs shaped together with customers at scale.
Capacity blended in from leading providers, so you scale beyond our own fleet whenever demand calls for it.
One blended fleet. Owned, custom, and partner capacity are combined behind a single API and matched to the right GPU for your workload - for the lowest cost per inference and the highest scalability, with nothing to own, name, or manage.
Reach out to secure capacity in the H2 2026 deployment - your model at production scale, for millions of users, with the best economics in the industry.
To request access to the Beta, tell us more about your needs.