FLUX.1 Kontext: AI-Powered Image Editing
Edit images with text instructions using the FLUX.1 Kontext API. Precise local edits, character consistency, and text replacement — available via Runware.


Introduction
Doing simple edits to an image has always been way harder than it should be. You need to learn Photoshop's million buttons, spend forever figuring out which tool does what, and even basic changes end up taking hours. The recent wave of AI tools promised to fix this, but most of them just created new problems. You still have to describe everything you want in detail, and half the time they change things you never asked them to touch.
Now Available: FLUX.1 Kontext [dev]
We've added support for FLUX.1 Kontext [dev], the newly released open-weights editing model from Black Forest Labs. This is the first generative image editing model of this quality made available without a proprietary license. It delivers precise local and global edits with strong character consistency, running on a 12B parameter model suitable for consumer hardware.
Available now on Runware with AIR ID: runware:106@1. It's fully compatible with our standard FLUX editing workflows and is roughly 2x cheaper than Kontext [pro] and 3.5x cheaper than [max], making it ideal for production systems requiring both quality and affordability. Perfect for iterative editing pipelines, fine-tuning workflows, and building custom LoRAs.
FLUX.1 Kontext is a new family of AI models (Dev, Pro and Max) that changes this completely. Instead of describing what you want to create, you simply tell it what you want to change. Need to make a car red? Just say "change the car color to red". Want to update the text on a sign? Tell it "change 'FOR SALE' to 'SOLD'" and it handles the rest while keeping everything else exactly the same.
A silver sports car parked under a neon-lit bridge at night, reflections on the wet asphalt, city skyline in the distance



A sleek futuristic house with floating glass panels, glowing blue edges, and a levitating front door platform, set on a clean white stone plaza with digital trees nearby, a floating "FOR SALE" hologram sign hovering near the entrance, soft evening light reflecting off chrome surfaces



FLUX.1 Kontext comes from Black Forest Labs, the team behind the original FLUX models. This represents a big shift toward natural language image editing. It keeps characters looking consistent when you move them to different scenes, preserves text styling when you change words, and lets you make multiple edits in sequence. You can build up complex changes step by step, with each edit building on the previous one without losing what you've already done.
What is FLUX.1 Kontext
Most AI editing tools work backwards. They make you describe the entire image you want to end up with, like you're commissioning a painting from scratch. FLUX.1 Kontext flips this around. You just tell the model what needs fixing in the current image, and it handles that specific thing while leaving everything else untouched.
Before instruction-based editing, we had image-to-image generation and inpainting tools. Image-to-image would try to recreate your whole picture based on a new prompt, often losing important details in the process. Inpainting let you mask specific areas to edit, but you still had to describe what you wanted in that spot, and the boundaries rarely looked natural. You'd end up with obvious seams where the new content met the original image, or colors that didn't quite match the lighting of the rest of the scene.
FLUX.1 Kontext introduces true instruction-based editing. Instead of regenerating entire images, it understands surgical commands. "Change the car color to red". "Remove the person in the background". "Replace the text on that sign". The model reads your existing image, understands your instruction, and modifies only what you've specifically asked for.
The model comes in three versions. FLUX.1 Kontext [max] and [pro] are available through partner API providers (we're one of them), while FLUX.1 Kontext [dev] is released with open weights under the same FLUX [dev] Non-Commercial License. This gives you options whether you want the convenience of an API or prefer to run the model yourself for research and experimentation. For commercial use of the dev version, you'll need to work with a licensed provider.
Real-world editing comparison
To demonstrate the difference between editing approaches, let's look at a real example. We have an image of a 3D stylized boy riding a bicycle and want to replace him with a panda while keeping everything else identical.
A 3D stylized boy riding a sky-blue bicycle in side view along a pastel-colored park path, rendered in a cute Pixar-like art style, soft shadows on the ground, the boy wears a yellow jacket and round glasses, smiling as he pedals, a wicker basket on the front of the bike filled with neatly arranged bamboo stalks tied with ribbon, warm daylight and cartoon-like trees in the background

FLUX.1 Fill [dev] (inpainting)
Does an excellent job blending the masked area seamlessly with the original image, but struggles to fully transform the boy into a panda. The original pixel information is too strong for the model to make such a dramatic change.

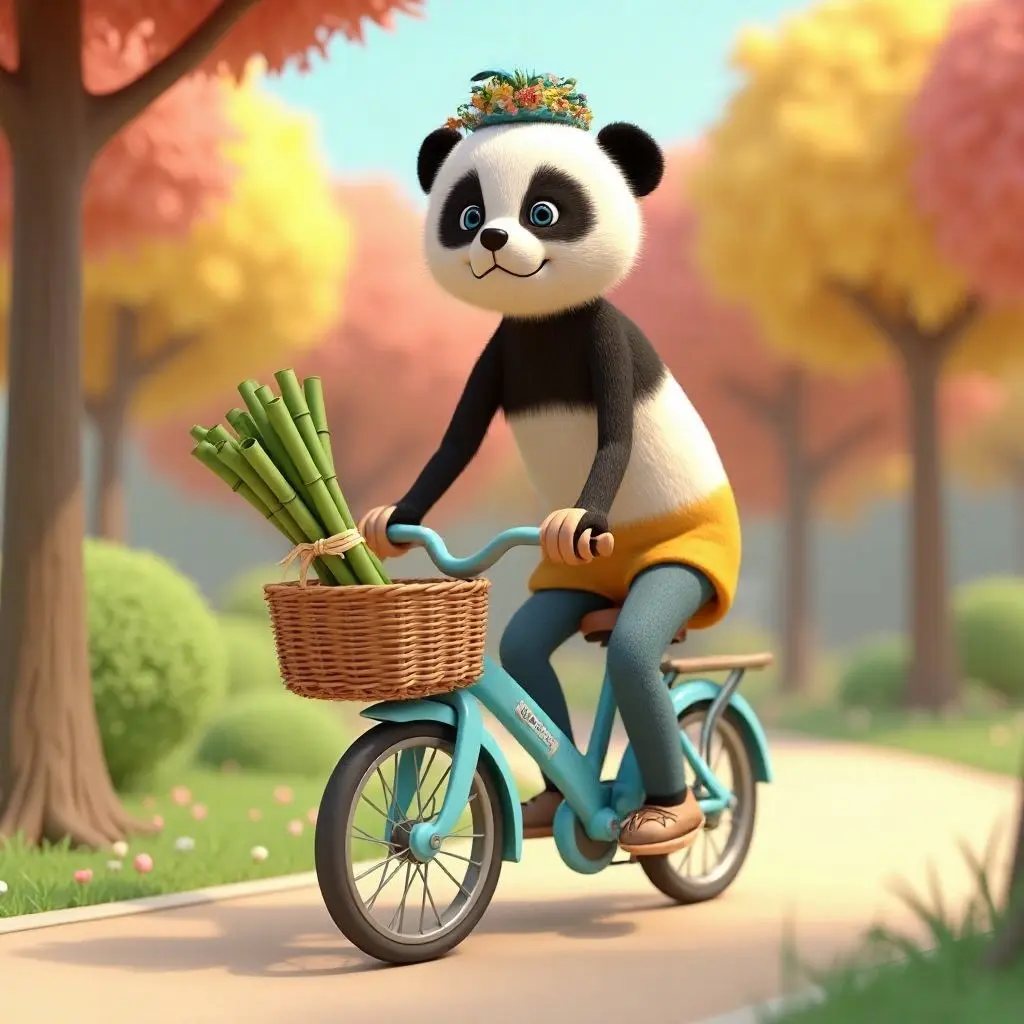

FLUX.1 [dev] (image-to-image)
Produces a convincing bicycle scene because the prompt includes all the scene details, but again can't make the precise character transformation we need. At 0.8 strength, it stays too close to the original. Push the strength higher, and the entire scene changes dramatically.



FLUX.1 Kontext [pro] (instruction-based)
Perfect results. Simply tell it "replace the boy with a panda" and it delivers exactly that. The panda naturally fits the scene, the lighting matches, and everything else stays untouched. It feels like magic because you get precisely what you asked for without losing anything you wanted to keep.



What makes this possible is a combination of diffusion technology and sophisticated instruction understanding. The model doesn't just process your text prompt. It analyzes the image, identifies objects and relationships within it, and figures out exactly what needs to change while preserving everything else.
Key capabilities and use cases
FLUX.1 Kontext's strength lies in understanding exactly what you want to change while preserving everything else. This surgical precision enables workflows that were previously impossible or extremely time-consuming.
Character consistency across scenes
The model excels at maintaining character identity across completely different environments. Take a photo of someone and place them as a chef in a restaurant kitchen or as an astronaut on Mars. The facial features, expressions, and distinctive characteristics remain perfectly consistent while everything else transforms around them.
Original
A photorealistic portrait of Albert Einstein, clearly showing his face, hair, and expression. Ideally front-facing or 3/4 angle, with minimal background clutter.
Variation 1 / 8

This opens up powerful workflows for storytelling and content creation. Instead of hiring models for multiple photo shoots or spending hours in Photoshop compositing different backgrounds, you can generate entire character narratives from a single reference image.
Precise object-level control
FLUX.1 Kontext understands what you're pointing at and can transport it between contexts. Take a logo and place it on a sticker. Take that sticker and apply it to a laptop. Take the laptop and position it in a coffee shop scene. Each step preserves the object's identity while naturally integrating it into the new environment with proper lighting, shadows, and perspective.
A rock band logo with bold gothic lettering saying "NEON STORM", electric blue and purple colors, lightning bolt accents, black background, heavy metal style





Product placement workflows become incredibly fluid with this capability. Brand asset management transforms when you can transport logos and graphics across different media and contexts while maintaining perfect integration.
Superior text editing
Most AI models struggle with text because they treat it like any other visual element. FLUX.1 Kontext understands that text has meaning and maintains the original typography, effects, and positioning while making precise changes.
A vibrant fruit juice pouch standing upright on a glossy pastel table, surrounded by floating slices of orange, kiwi, and passionfruit, the pouch has the word 'RUNWARE' in large bubbly gradient letters with a soft drop shadow, warm ambient lighting and summer ad feel


A high-end GPU graphics card on a lit display pedestal, the metal frame has the word 'RUNWARE' engraved in a sleek chrome font on the side, styled like a product reveal ad


A vintage 1970s circus movie poster with the title 'RUNWARE' in large curved red and gold letters with ornamental swirls and star outlines, a cheerful elephant balancing glowing computer GPUs on its trunk


This precision makes FLUX.1 Kontext particularly valuable for commercial workflows. E-commerce businesses update product images with different text elements. Design agencies adapt client materials for different markets while preserving all the visual branding and design work.
Iterative editing workflows
Unlike traditional tools where each edit risks undoing previous changes, you can build complex transformations step by step. This iterative approach transforms how designers work. Instead of trying to describe a complex final vision in one prompt, you can explore ideas progressively.
Original
A cute 3D-rendered fruit stall, with neatly arranged fruits on wooden crates: a curved yellow banana, a round orange, a spiky pineapple, and a shiny red apple. Each fruit is clearly shaped and spaced, under a striped canopy with colorful flags.
Iteration 1 / 4

Single instruction: Replace the banana with a mango in the same position, add the word 'FRUIT' in uppercase white letters on the front of both wooden crates, paint the wooden crates green while keeping their structure and lighting consistent, and add silly googly eyes to every fruit in the scene.
The single complex instruction produces impressive results but sometimes mixes certain things — it might remove unintended objects or add text to the wrong place. The iterative approach gives you control at every step, letting you verify each change before building on it.



Style transfer and transformations
The model understands artistic styles deeply enough to transform images while preserving their essential structure. Convert a photograph to anime style and the characters remain recognizable. Transform a scene into an oil painting and the composition stays intact while gaining painterly qualities.
Original
Original image
Variation 1 / 10

How FLUX.1 Kontext compares to other models
2025 has been a breakthrough year for instruction-based image editing. Several major models have emerged, each with different strengths and trade-offs.
| Model | Speed | Price per Image | Availability | License | Character Consistency | Text Preservation |
|---|---|---|---|---|---|---|
| FLUX.1 Kontext [dev] | ~6-10s | TBD | Open Weights | Non-Commercial | Excellent | Excellent |
| FLUX.1 Kontext [pro] | ~8-10s | $0.04 | API Only | Commercial | Excellent | Excellent |
| FLUX.1 Kontext [max] | ~10-12s | $0.08 | API Only | Commercial | Excellent | Excellent |
| ByteDance BAGEL | ~40s | $0.10 | Open Source | Apache 2.0 | Good | Good |
| ByteDance BAGEL (Thinking) | ~40-50s | $0.12 | Open Source | Apache 2.0 | Good | Good |
| OpenAI GPT-4o (Image-1) | ~30s | $0.045 | API Only | Commercial | Limited | Poor |
| Google Gemini (Flash) | ~15-20s | $0.04 | API Only | Commercial | Weak | Poor |
| HiDream E1 | ~40s | $0.06 | Open Source | MIT | Good | Fair |
| Stepfun Step1X-Edit | ~30s | $0.03 | Open Source | Apache 2.0 | Good | Good |
Performance and cost comparison
Speed and pricing determine what you'll actually use in practice. It doesn't matter how good a model is if it's too slow or expensive for your regular workflow.
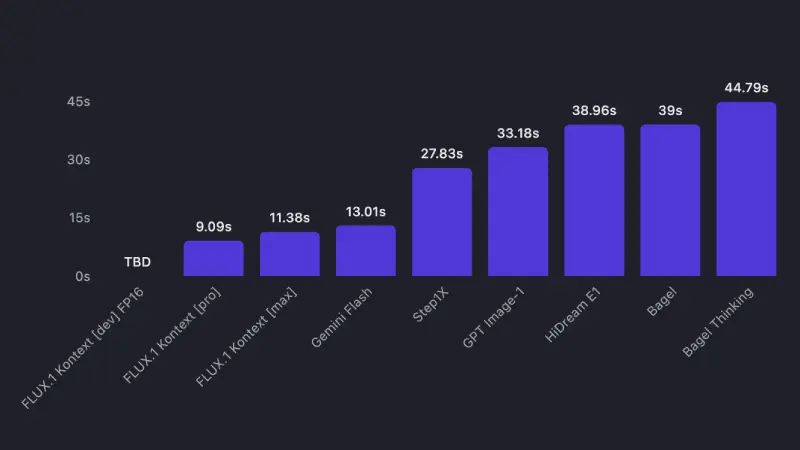
Speed matters because instruction-based editing is inherently iterative. You make one edit, see the result, then make another. When each generation takes 30+ seconds like GPT Image-1, this back-and-forth becomes painfully slow. FLUX.1 Kontext's sub-10-second times keep you in the creative flow.
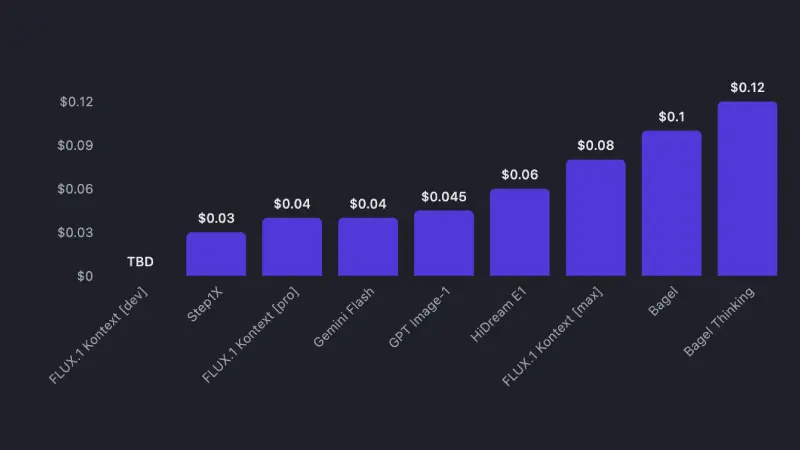
The deployment reality
Most open-source models still require serious hardware. While having access to model weights is great, actually running these models demands enterprise-grade GPUs that most people don't have.
The advantage of having multiple API options is flexibility. Different providers offer different pricing, policies, and availability. You can choose based on your specific needs rather than being locked into a single platform's constraints.
Getting the best results from instruction-based editing
FLUX.1 Kontext thinks differently than traditional AI models. Instead of describing entire scenes, you're giving editing instructions to something that already understands what's in your image. This changes how you should write prompts.
Instruction verbs that work well
FLUX.1 Kontext responds best to clear action verbs. Here are the most effective ones.
For modifications: "Change", "Make", "Transform", "Convert"
- "Change the sky to sunset"
- "Make the walls brick"
- "Convert to black and white"
For additions: "Add", "Include", "Put"
- "Add sunglasses to the person"
- "Put mountains in the background"
For removals: "Remove", "Delete", "Take away"
- "Remove the person in the background"
- "Delete the text from the sign"
For replacements: "Replace", "Swap", "Substitute"
- "Replace 'OPEN' with 'CLOSED'"
- "Swap the blue car with a red truck"
For positioning: "Move", "Place", "Position"
- "Move the person to the left side"
- "Place a tree behind the house"
Simple instruction templates
These patterns work for most common editing tasks. Start with these frameworks and add more details as needed.
Object modification: "[Action] the [object] to [description]"
- "Change the car to red"
- "Make the building taller"
Text replacement: "Replace '[old text]' with '[new text]'"
- "Replace 'SALE' with 'SOLD'"
Style changes: "Convert to [style] while maintaining [what to preserve]"
- "Convert to watercolor while maintaining the composition"
Character edits: "Change the [person description] to [change] while preserving [identity features]"
- "Change the woman with blonde hair to wearing a red dress while preserving her facial features"
Start simple and be specific
FLUX.1 Kontext excels at iterative editing, not scene recreation. Don't try to make five changes in one instruction. Start with the most important edit, see the result, then add the next change. The model has a 512 token maximum for prompts.
- Step 1: "Change to daytime"
- Step 2: "Add people walking on the sidewalk"
- Step 3: "Make the building walls brick"
Text editing has special rules
Use quotation marks around the specific text you want to change. This tells Kontext you're doing text replacement, not adding new text elements.
- Good: Replace "SALE" with "SOLD"
- Less effective: Change the sign to say SOLD instead of SALE
Pro tip: If you want to preserve the original styling, add "while maintaining the same font style and color". Complex or stylized fonts work better when you explicitly ask to preserve their characteristics.
Style transfer needs specific language
Name the exact style you want. "Make it artistic" is too vague. "Convert to watercolor painting" or "Transform to pencil sketch with cross-hatching" gives Kontext clear direction.
When using style references: If you have a reference image with a specific style, use prompts like "Using this style, [describe what you want to generate]". This works especially well with FLUX.1 Kontext [pro].
Composition control prevents unwanted changes
Simple background changes can accidentally move your subject. Instead of "put him on a beach", try "change the background to a beach while keeping the person in the exact same position, scale, and pose".
When you want surgical precision: Add phrases like "maintain identical subject placement" or "only replace the environment around them" to prevent unwanted repositioning.
Common troubleshooting
When editing people, avoid pronouns. Instead of saying "make her hair longer," say "make the woman with short black hair have longer hair". Kontext needs clear identity markers to maintain consistency across edits.
If Kontext changes too much: Be more explicit about what should stay the same. Add "while maintaining all other aspects of the original image" or "everything else should remain unchanged".
If character identity drifts: Use more specific descriptors and avoid broad transformation verbs. "Change the clothes to medieval armor" works better than "transform into a medieval character".
If style transfer loses important details: Describe the visual characteristics of the style you want. "Convert to oil painting with visible brushstrokes, thick paint texture, and rich color depth" preserves more scene information than just "make it an oil painting".
Conclusion
FLUX.1 Kontext isn't just another AI model release. It's the moment image editing finally works the way people actually think. No more describing entire scenes just to change one thing. No more losing character consistency when moving someone to a new background. No more spending two minutes drawing an inpainting mask just to fix a shirt color.
The instruction-based approach changes everything. Instead of fighting with prompts or learning clunky interfaces, you simply tell the model what's wrong with the image. It listens, understands, and fixes exactly that. Nothing more, nothing less.
While other model lock you into cloud services with usage caps or require enterprise hardware with sky-high costs, FLUX.1 Kontext gives you real options. Want the ease of an API? Use max or pro. Need the freedom to experiment? Grab the dev weights. Want both, and commercial rights too? You're in the right place.
This is what the future of creative tools looks like. It's fast enough for real-time edits, smart enough to keep what matters intact, and cheap enough that you can refine your results step by step.
The technology finally works the way creatives do.